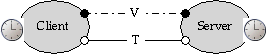
A 6.852 Term Project by Rafal Boni, Rohit Khare, and Matthew S. Levine
The proposal below is out-of-date. We moved the project to LaTeX and produced a report, Formal Modeling of a Resource-Leasing Extension to HTTP. The sources are also available, including a halfway-translated HTML version.
Resource-leasing can be mapped naturally into HTTP/1.x semantics; the next step will be for me (Rohit) to present these results as an Internet-Draft.
By modelling a network of HTTP agents as asynchronous network automata (with access to clocks), we can clearly articulate the power and limits of Web-based computation. In particular, we investigate the power of suitably extended HTTP clients and servers to:
The World Wide Web is a ubiquitous application on the global Internet, which inherits many of the Internet's limitations. It operates in an environment beset by host failures, link failures, even Byzantine errors. By expressing HTTP in a formal context, we hope to identify the exact powers and limits of Web-based applications.
Its strict client-server model can be strengthened by adding server-to-server communications channels. By extending the model to incorporate a selected set of messages between servers, we hope to provide tighter bounds on caching, for example.
The foundation work for this project is an effort to formalize HTTP servers, clients, proxies, caches, and resources as a collection of automata. After some investigation, we have come up with a unique model for HTTP:
Each HTTP automaton has a local clock, running at the same global rate. Our model of the Internet connection between them uses two channels: a virtual channel ``V'' used to request TCP connections on ``T''. We believe V is unreliable, not FIFO, and that T is reliable, FIFO, but can stop.
Details of the Model
In HTTP uses a notion of universal ``real'' time. Furthermore, every process has a clock, which is related to real time, allowing HTTP automata to reliably measure intervals. Since none of the formal models in the book include such a notion, we need to specify our own formal model.
We start with the asychchronous network model, that is, a collection of ``process'' I/O automata and ``channel'' I/O automata. We add to each process automaton a ``clock'', something that reports a time. We do not assume that the clocks report real time, but we do assume that they run at the same rate as real time. Thus processes can agree on intervals of time, although not necessarily on the current time.
The channels are a little strange. We put two channels between each pair of nodes, each having different properties. The first channel type, ``V'', is unreliable and not FIFO. A message must be sent and received over this channel as a prerequisite to using the second channel, ``T'', which is FIFO but subject to stopping failures. This is to model setting up a TCP connection, which is unreliable, versus using a TCP connection, which is reliable up to being broken, or timing out. We assume that it is not reasonable to hold the T channel for long, so for some problems we will require that it be dropped and reacquired when needed.
For failures, we will consider stopping failures on the the T channels and of the processes. In some cases we will want to consider the case that a stopped process or channel gets restored.
As a partial introduction to HTTP, we modeled some of the messages that are sent on the T channel between clients and servers.
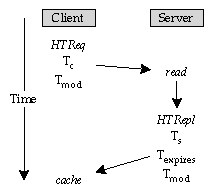
Clients initiate action by making an HTRequest, which specifies a method, the time of the request, Tc, (according to the client), and (if the client has a cached copy), the client's belief of the last-modify time of the resource, Tmod, (according to the server). The server reads the request, and some time later, prepares an HTReply that includes the resource, the time of service, the server's expectation of how long the returned resource is valid for, and the server's belief of the last-modify time.
Request methods include: GET, GET-If-Modified-Since (conditional get), HEAD (return only headers & time information), and the possibly-atomic PUT, POST, and DELETE transactions. Responses can include the resource (200-class), or notice that the resource continues to be valid (304 Not Modified).
There are many proposals to layer more information atop this basic structure: hash-based document validators, advisory maximum-age values, and new Cache-control: messages. We will be investigating some of these.
One interesting problem is how to allow ``check out'' of resources. It would be nice if a client could tell a server to lock some resource, such that the client could modify it and return the new version to the server without any other clients modifying the resource in the elapsed time. This is approximately mutual exclusion, so it is surely impossible in a faulty, asynchronous network, but there may be workable solutions based on leasing the resource for a finite interval.
We point to a resource on a server using a URI (Unversal Resource Identifier). Of the several HTTP methods applicable to a resource, some are potentially-modifying transactions: PUT, POST, etc. Clients should be able to aquire leases or locks from a server to prevent other clients from attempting transactions on a resource for the duration.
Note that those requirements above don't encode some additional heuristic properties: that checkout is for ``human'' time periods, as for document-editing; that the T channel is not held open for the life of the lease; and that there may be high contention for the lease, and fairness may be desirable.
We would like to extend the HTTP protocol with new methods to allow a client to request, and new responses for a server to vend, leases on resources that guard against certain transactions. We would like leases to be in effect for time periods >> lifetime of a T connection, which means that it must be proof against process failure, channel failure, and the V-channel properties. Finally, any solution should try to remain stateless, like HTTP.
A lease is granted for a fixed interval, measured in the server's frame. The lease expires after the interval and before the next lock request, if it is not voluntarily concluded earlier.
For the particular case of document editing, we may show the interactions with an underlying version control system. A workable solution may also have to introduce a backchannel for the server to query the leaseholder's liveness.
We will also have to investigate timing dependencies in such solutions: what are the bounds on accuracy: round-trip delay times? relative skew? We believe that the solution to this problem will work well for extended times, but not for fine-grained locking as for IV, Atomic Transactions.
To provide fairness properties, we might be able to adapt the Lamport Bakery algorithm to maintain a queue of waiting processes -- the twist is dealing with dead ticket-holding processes and ones that don't ``return to the counter'' within a timeout.
Caching of documents by servers, proxies, and clients is absolutely essential to the future scaling of HTTP service. Currently, there is a patchwork of rules that cover the cacheability of responses and the ability to service requests with a cached copy. While there are many engineering parameters driving the debate (usage patterns, replication cost, usage tracking and measurement), there are also formal aspects of the problem: timing assumptions, confidence intervals, and bounds in the face of failure.
A requesting agent (a client or a proxy) has access to a cache of previously-requested resources, and prefers to use the entity available locally if it believes the local copy is ``correct''.
In practice, various pieces of timing information may be available: the time the local copy was generated (``age''), its expiry interval, and the last-modify time of the entity. Other kinds of ``validator'' tokens are available: the length, a hash value, or an opaque value provided by the server.
From this, we would like to provide correctness predicates, time-error bounds, and a workable protocol to tighten the bounds, perhaps by leasing a subscription to invalidation notices.
By formally stating the logic embedded in the 1.1 caching spec, we plan to demonstrate the time-bounds on getting correct responses from a cache. We expect to experiment with a back-channel for cache-invalidation notifications and see if that yields tighter bounds.
Another related problem is multiple transactions with different servers that appear atomic. For example, you might want to purchase both an airline ticket and reserve a hotel, but not either.
We have reserved this problem for last, because it seems to be the most open to analysis; we have not yet developed a hypothetical solution. We are, though, gaining a clear understanding of the scenarios and typical Internet failure modes.
There are two practical subcases: first, for atomic transactions to a single resource, and for transactions on two servers. For the first case, the server can implement a monitor on the resource that serializes transaction operations; the client would receive a lock with a T-channel rather than a long-term lease. For the second, we seem to have reduced it to solving the agreement problem between two nodes on a T-channel; we are curious if there are TCP properties that can help solve this agreement problem.
An impossibility result here would be equally important.
We expect to draw directly from experience in the Web community, academic research on the power of partially synchronous systems, and experience with distributed systems services (filesystems, directory services).
These are all topics of current debate in the HTTP design community, so we also expect to refer to the online discussion archives, as well as individual proposals for caching, etc.
We have also identified a few relevant papers, books, and systems.
The Echo Distributed File System
Existing literature on two-phase-commit and presumed commit
Experience with WAN locking in VMS